
音源分离截图
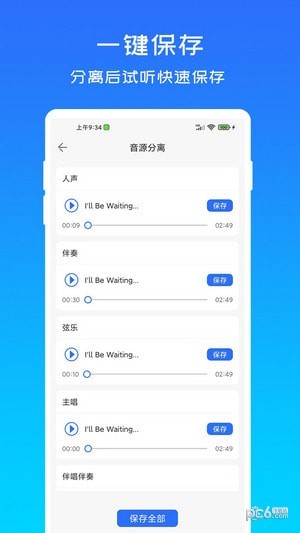
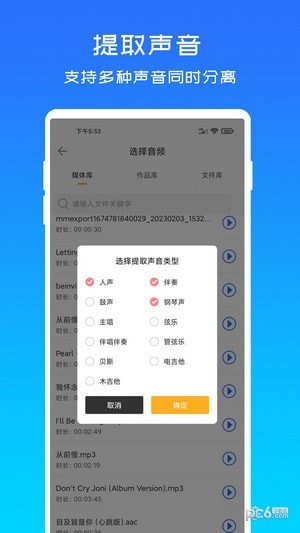
音源分离介绍
音源分离软件是一款非常好用功能强大的音频处理工具。音源分离软件可以帮助用户轻松从音频文件中分离出音乐和人声。具有先进的算法和用户友好的界面,可以轻松地将音频文件分离为多个独立的音频轨道,方便地进行后续处理。
音源分离软件介绍
采用先进的深度学习算法,能够在毫秒级别内准确分离音频中的各个声音成分,能够智能地区分不同种类的声音,例如歌曲中的人声、背景音乐、鼓点等,支持批量处理,用户可以同时处理多个不同格式的音频文件。
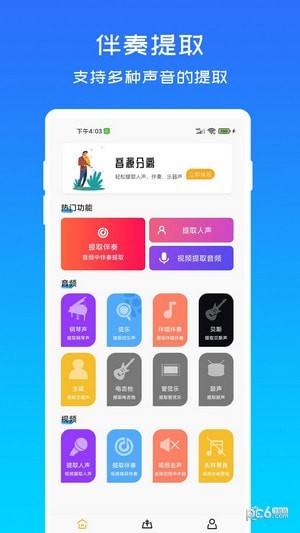
音源分离软件特色
1、操作简单易懂,用户只需要轻松几步即可提取出所需声音成分;
2、提供多种定制化设置,可根据用户需要调整各项处理参数;
3、可以输出高质量的音频文件格式,包括WAV、mp3、FLAC等。
音源分离软件功能
1、将提取的声音成分保存到云端,方便随时使用和分享;
2、采用实时处理技术,可以在处理过程中随时预览效果;
3、通过插件方式与其他音频软件进行集成,扩展应用场景。
音源分离软件亮点
1、可以自动识别和去除音频中的杂音和失真,提高处理效果;
2、提供详细的用户使用指南和技术支持,可以轻松上手;
3、支持多种音频分离模式,用户可以灵活选择。
展开
信息
- 版本: v1.0.1
- 分类:影音播放
- 语言:简体
- 平台: 安卓
- 大小: 54.9M
- 授权:免费
- 作者:
- 时间:2023-05-17
- 人气:9026
- 下载:660
相关资讯
